AI 코딩을 더 잘하기 위한 작업 설계 방식
AI가 새로운 패러다임인 것은 맞지만, 좋은 소프트웨어 엔지니어링의 기본 원칙은 여전히 중요하다. 오히려 AI와 일할 때 더 중요해진다.
발표자는 AI 코딩을 단순히 “스펙을 주면 코드가 나온다”는 식으로 보지 않습니다. 대신 작은 작업 단위, 명확한 설계 개념, PRD, 칸반 보드, 테스트 루프, 코드 리뷰, 병렬 에이전트를 조합해 AI를 실무 개발 프로세스 안에 넣는 방법을 설명합니다.



1. 도입: AI 시대에도 소프트웨어 엔지니어링 기본기는 중요하다
발표자는 자신을 AI를 가르치는 교사라고 소개하며, 이번 워크숍의 전제를 설명합니다. 참석자들에게 AI로 코딩해본 경험, 매일 사용하는지, AI 때문에 답답했던 경험이 있는지 묻습니다.
핵심 메시지는 AI가 완전히 새로운 도구이지만, 인간과 협업할 때 중요했던 소프트웨어 엔지니어링의 원칙이 AI와 일할 때도 그대로 작동한다는 점입니다.
주요 발언
“우리는 AI가 새로운 패러다임이라고 생각하지만, 인간과 일할 때 중요한 소프트웨어 엔지니어링의 기본 원칙이 AI와도 아주 잘 작동한다는 사실을 잊고 있다.”
2. LLM의 첫 번째 제약: Smart Zone과 Dumb Zone
발표자는 LLM에는 잘 작동하는 구간과 성능이 떨어지는 구간이 있다고 설명합니다. 이를 Smart Zone / Dumb Zone으로 표현합니다.
새 대화를 시작했을 때, 즉 컨텍스트가 깨끗할 때 LLM은 가장 좋은 성능을 냅니다. 하지만 대화가 길어지고 토큰이 많아질수록 attention 관계가 복잡해지고, 일정 지점 이후에는 판단 품질이 떨어진다고 설명합니다.
발표자는 대략 100k 토큰 근처를 하나의 기준으로 보고, 1M 컨텍스트가 있어도 코딩 작업에서는 무작정 긴 컨텍스트를 쓰는 것이 좋은 방식은 아니라고 말합니다.
주요 발언
“LLM은 처음 새 대화를 시작했을 때 가장 좋은 일을 한다.”
“같은 컨텍스트 창에 계속 내용을 추가하면 점점 더 멍청해진다.”
“우리는 작업 크기를 Smart Zone 안에 들어오도록 설계해야 한다.”
3. 큰 작업을 작은 작업으로 나누는 방법
큰 작업을 AI에게 한 번에 맡기면 Dumb Zone에 들어갈 위험이 커집니다. 발표자는 과거에는 multi-phase plan, 즉 여러 단계로 나눈 계획을 사용했다고 설명합니다.
하지만 단순한 phase 1, phase 2, phase 3 방식은 결국 순차 루프일 뿐입니다. 여기서 발표자는 Ralph Wiggum 방식을 언급합니다. 이는 PRD 같은 목적지를 정한 뒤, AI에게 “목적지에 가까워지는 작은 변경을 반복하라”고 시키는 방식입니다.
다만 발표자는 이 방식이 어느 정도 작동하긴 하지만, 더 많은 구조가 필요하다고 봅니다.
주요 발언
“큰 작업을 작은 섹션으로 쪼개서 각 작업이 Smart Zone 안에서 처리되게 해야 한다.”
“목적지를 정하고, AI에게 그곳에 가까워지는 작은 변경을 계속하게 할 수 있다.”
“Ralph 방식은 어느 정도 작동하지만, 나는 조금 더 구조화된 방식을 선호한다.”
4. LLM의 두 번째 제약: LLM은 계속 잊어버린다
발표자는 LLM을 영화 「메멘토」의 인물처럼 설명합니다. 컨텍스트를 지우면 LLM은 다시 시스템 프롬프트 상태로 돌아갑니다.
일반적인 AI 코딩 세션은 다음 흐름을 가집니다.
- 시스템 프롬프트
- 코드베이스 탐색
- 구현
- 테스트와 피드백 루프
발표자는 시스템 프롬프트가 너무 크면 시작부터 Dumb Zone에 들어갈 수 있기 때문에, 가능한 작게 유지해야 한다고 말합니다.
주요 발언
“LLM은 메멘토의 남자 같다. 계속 기본 상태로 리셋된다.”
“시스템 프롬프트는 가능한 작아야 한다.”
“컨텍스트를 clear하면 모든 것이 사라지고 다시 시작점으로 돌아간다.”
5. Compacting에 대한 비판
발표자는 compacting, 즉 긴 대화를 요약해서 컨텍스트를 줄이는 방식을 설명합니다. 개발자들은 compacting을 좋아하지만, 발표자는 선호하지 않는다고 말합니다.
이유는 compacting을 하면 이전 대화의 흔적이 요약 형태로 남고, 그 요약이 다시 쌓이면서 불필요한 “침전물”이 생긴다고 보기 때문입니다. 발표자는 오히려 매번 깨끗한 상태로 돌아가는 편이 더 예측 가능하다고 봅니다.
주요 발언
“개발자들은 compacting을 좋아하지만, 나는 싫어한다.”
“나는 AI가 메멘토의 남자처럼 행동하는 편을 더 좋아한다. 매번 같은 상태로 돌아가기 때문이다.”
6. 실습 배경: 코스 플랫폼에 게이미피케이션 기능 추가하기
워크숍에서는 Course Management Platform, 즉 강사와 학생을 위한 CMS 형태의 앱을 사용합니다.
클라이언트 브리프는 다음과 같습니다.
학생들이 가입 후 몇 개의 레슨만 듣고 이탈한다. 그래서 플랫폼에 게이미피케이션 기능을 추가하고 싶다는 요청입니다.
발표자는 이 모호한 아이디어를 실제 기능으로 바꾸기 위해 AI와 어떻게 협업할지 보여줍니다.
주요 발언
“아이디어를 받았을 때, 그것을 현실로 바꾸는 방법이 필요하다.”
7. Specs to Code 방식에 대한 비판
발표자는 “스펙을 쓰고, AI에게 넘기면 코드가 나온다”는 식의 접근을 비판합니다.
이 방식은 결과 코드에 문제가 생겼을 때 코드를 보지 않고 다시 스펙만 고치는 흐름이 됩니다. 발표자는 이것을 사실상 다른 이름의 vibe coding이라고 봅니다.
그는 코드를 계속 이해하고, 붙잡고, 설계해야 한다고 강조합니다.
주요 발언
“Specs to code를 정말 시도해봤지만, 별로였다. 작동하지 않는다.”
“코드를 계속 붙잡고 있어야 한다. 코드를 이해해야 하고, 코드를 형성해야 한다.”
“코드는 당신의 전장이다.”
8. Grill Me Skill: AI와 공유된 이해 만들기
발표자는 거의 모든 AI 작업을 Grill Me Skill로 시작한다고 말합니다.
이 스킬은 AI가 사용자에게 계속 질문하게 만듭니다. 목적은 바로 계획서를 만드는 것이 아니라, AI와 사람이 같은 이해에 도달하는 것입니다.
예를 들어 게이미피케이션 기능을 만들 때 AI는 다음과 같은 질문을 던집니다.
- 어떤 행동에 포인트를 줄 것인가?
- 기존 학습 기록에도 포인트를 소급 적용할 것인가?
- 레벨 progression curve는 어떻게 할 것인가?
- streak은 포인트를 주는가?
- 게이미피케이션 UI는 어디에 위치하는가?
발표자는 이 질문들이 매우 중요하다고 봅니다. 클라이언트나 개발자가 미처 생각하지 못한 결정을 AI가 끌어내기 때문입니다.
주요 발언
“나는 asset도, plan도 필요하지 않았다. AI와 같은 파장에 올라타는 것이 필요했다.”
“공유된 이해에 도달해야 한다.”
“이것은 AI와 작업을 시작하는 매우 효과적인 방식이다.”
9. Sub-agent의 역할
Grill Me 과정에서 AI는 sub-agent를 호출해 코드베이스를 탐색합니다. 발표자는 sub-agent를 별도 컨텍스트 창을 가진 위임형 LLM이라고 설명합니다.
Sub-agent는 많은 토큰을 사용해 코드베이스를 깊게 탐색한 뒤, 핵심 요약만 parent agent에게 전달합니다. 이렇게 하면 메인 컨텍스트를 상대적으로 깨끗하게 유지하면서도 탐색 결과를 활용할 수 있습니다.
주요 발언
“Sub-agent는 일종의 위임이다.”
“다른 LLM이 독립된 컨텍스트 창에서 작업하고, 중요한 내용만 부모 에이전트에게 보고한다.”
10. Human-in-the-loop와 AFK Task 구분
발표자는 AI 시대의 작업을 두 가지로 나눕니다.
첫째, Human-in-the-loop 작업입니다. 사람이 반드시 참여해야 하는 작업입니다. 대표적으로 기획, 의사결정, 요구사항 정렬, 도메인 판단이 여기에 들어갑니다.
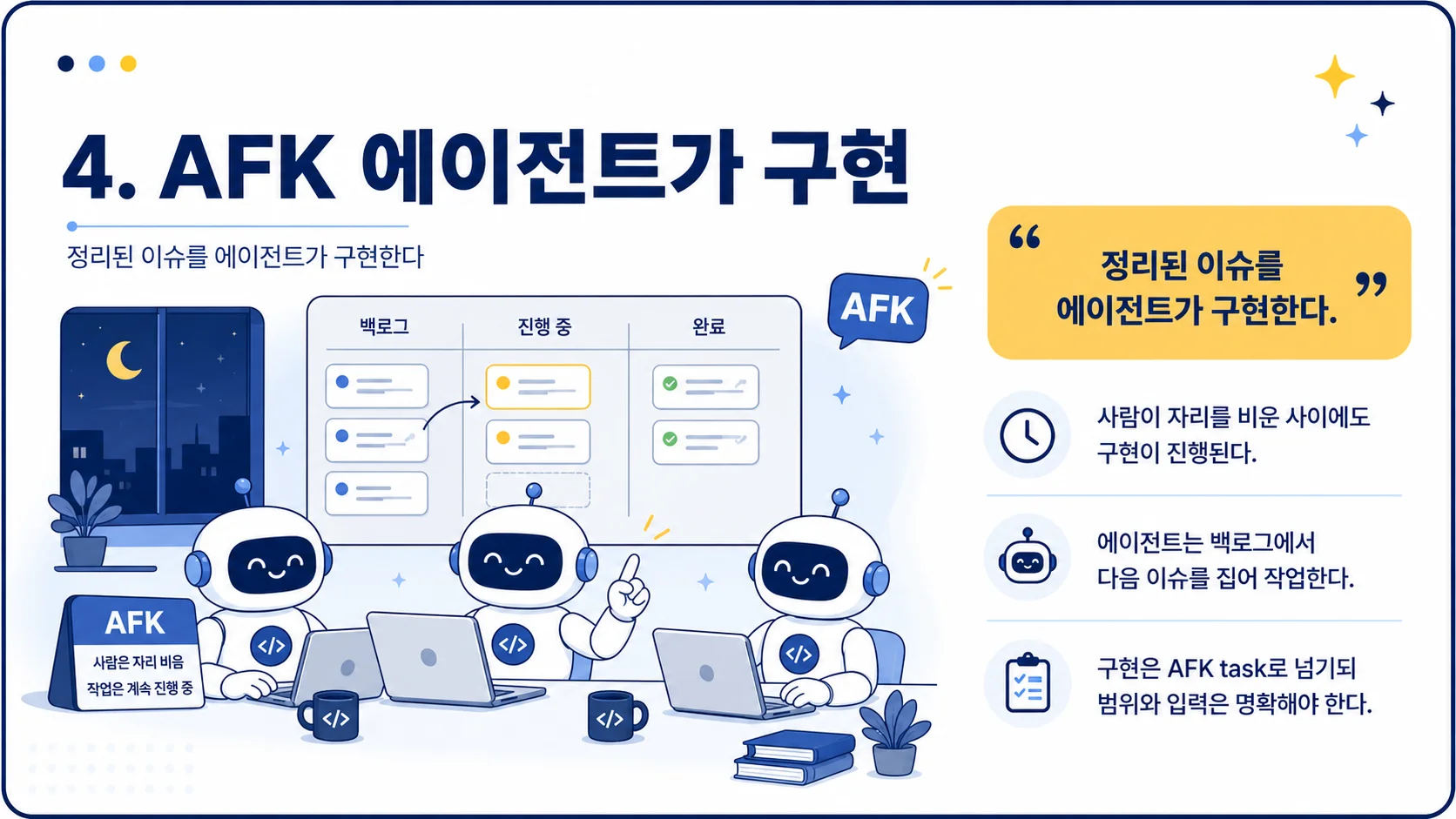
둘째, AFK 작업입니다. Away From Keyboard, 즉 사람이 자리를 비워도 되는 작업입니다. 구현 단계는 조건만 잘 갖추면 AFK 작업으로 넘길 수 있다고 설명합니다.
주요 발언
“AI 시대에는 두 종류의 작업이 있다. 사람이 직접 루프 안에 있어야 하는 작업과, 사람이 키보드에서 떨어져 있어도 되는 AFK 작업이다.”
“기획과 정렬 단계는 반드시 Human-in-the-loop여야 한다.”
“구현은 AFK 작업으로 바꿀 수 있다.”
11. PRD: 목적지를 문서화하기
Grill Me 세션이 끝나면 그 대화를 PRD로 정리합니다. 발표자는 PRD를 Destination Document, 즉 목적지 문서라고 부릅니다.
PRD에는 다음이 들어갑니다.
- 문제 정의
- 사용자가 겪는 문제
- 해결 방향
- 사용자 스토리
- 구현 결정
- 테스트 결정
- 범위 밖 항목
발표자는 Grill Me를 먼저 하고 PRD를 작성하는 방식을 선호합니다. 이미 AI와 공유된 설계 개념이 형성되어 있기 때문에, PRD는 그 이해를 정리하는 문서가 됩니다.
주요 발언
“PRD의 기능은 목적지 문서다.”
“우리가 지금까지 만든 design concept을 요약하는 것이다.”
“나는 먼저 Grill Me를 하고, 그 다음 PRD를 작성하는 것을 좋아한다.”
12. PRD를 굳이 꼼꼼히 읽지 않는 이유
흥미롭게도 발표자는 AI가 생성한 PRD를 꼼꼼히 읽지 않는다고 말합니다.
그 이유는 Grill Me 과정을 통해 이미 AI와 같은 이해에 도달했기 때문입니다. 이 상태에서 PRD를 읽는 것은 사실상 AI의 요약 능력을 검증하는 것에 가깝다고 봅니다.
물론 실제 조직에서는 검토가 필요할 수 있지만, 발표자 개인의 워크플로우에서는 PRD 자체보다 그 전 단계의 공유된 이해가 더 중요합니다.
주요 발언
“나는 이 문서들을 읽지 않는다.”
“이미 LLM과 같은 파장에 도달했다면, PRD를 읽는 것은 LLM의 요약 능력을 확인하는 것일 뿐이다.”
13. 나쁜 코드베이스는 나쁜 에이전트를 만든다
Q&A에서 발표자는 코드 이해의 중요성을 다시 강조합니다. AI가 TypeScript를 고쳐주고 타입 오류를 해결할 수 있어도, 개발자는 여전히 코드와 도구를 깊이 이해해야 한다고 말합니다.
특히 코드베이스 자체가 엉망이면, 그 안에서 작업하는 AI도 좋은 결과를 내기 어렵다고 강조합니다.
주요 발언
“나쁜 코드베이스는 나쁜 에이전트를 만든다.”
“쓰레기 코드베이스가 있으면, 그 코드베이스에서 작업하는 에이전트에게서도 쓰레기가 나온다.”
14. PRD를 칸반 보드로 바꾸기
PRD가 목적지 문서라면, 그 목적지까지 가는 여정은 칸반 보드로 설계합니다.
발표자는 단순한 순차 계획보다 칸반 보드가 낫다고 봅니다. 이유는 각 작업 간의 blocking 관계를 명시할 수 있고, 병렬 작업이 가능해지기 때문입니다.
각 이슈는 독립적으로 집어갈 수 있어야 합니다. 어떤 작업은 먼저 끝나야 하고, 어떤 작업은 동시에 진행할 수 있습니다.
주요 발언
“목적지를 문서화하는 문서가 필요하고, 여정을 문서화하는 문서가 필요하다.”
“순차 계획은 한 명의 에이전트만 작업할 수 있다.”
“칸반 보드는 작업의 의존 관계를 드러내고, 병렬화를 가능하게 한다.”
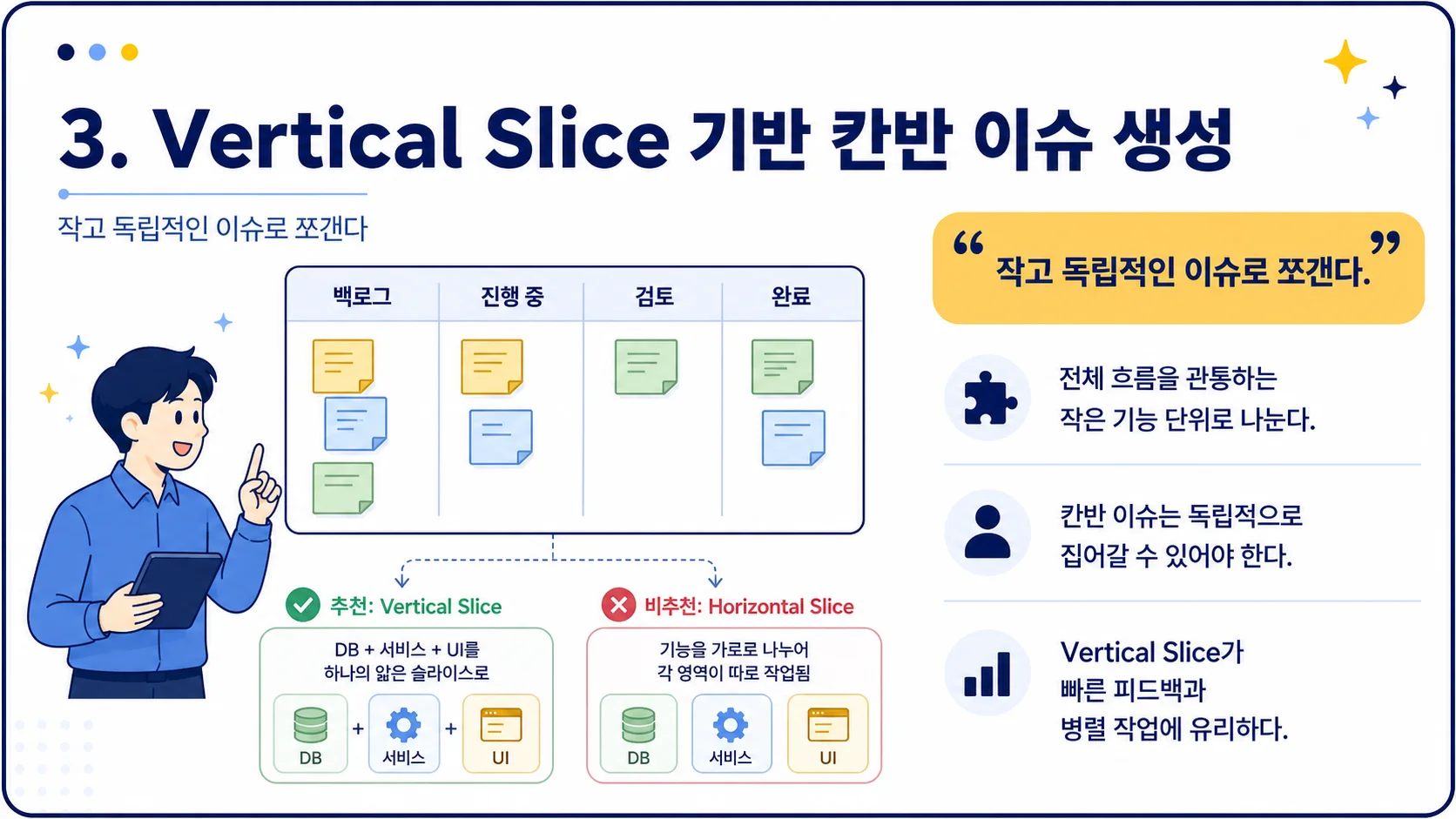
15. Vertical Slice와 Tracer Bullet
발표자는 AI가 기본적으로 수평적으로 코딩하려는 경향이 있다고 말합니다.
예를 들어 1단계에서 DB 스키마, 2단계에서 API, 3단계에서 프론트엔드를 만드는 식입니다. 하지만 이 방식은 전체 흐름을 끝까지 연결해보기 전까지 피드백을 받을 수 없습니다.
그래서 발표자는 Vertical Slice, 즉 얇지만 전체 계층을 관통하는 기능 단위를 선호합니다.
예를 들어 “레슨 완료 시 포인트를 지급하고, 대시보드에 최소한으로 표시하기” 같은 작업은 DB, 서비스, UI를 모두 통과하는 작은 완성 흐름입니다.
주요 발언
“AI는 수평적으로 코딩하는 것을 좋아한다.”
“하지만 그렇게 하면 phase 3이 끝나기 전까지 전체 흐름에 대한 피드백을 받을 수 없다.”
“우리는 모든 레이어를 가로지르는 얇은 기능 조각을 만들어야 한다.”
“Tracer bullet은 우리가 어디를 조준하고 있는지 피드백을 주는 방식이다.”
16. 구현 단계: 인간은 루프에서 빠지고 AI가 작업한다
아이디어 → Grill Me → PRD → 칸반 보드까지는 사람이 검토합니다. 하지만 구현 단계에서는 사람이 한발 물러나고, AI 에이전트가 칸반 보드의 이슈를 하나씩 처리합니다.
발표자는 이것을 Day Shift / Night Shift 비유로 설명합니다.
사람은 낮 근무처럼 계획하고 정렬하고 작업을 준비합니다. AI는 밤 근무처럼 준비된 이슈를 처리합니다.
주요 발언
“이 지점에서 인간은 루프를 떠난다.”
“우리는 많은 시간을 기획에 썼지만, 그 덕분에 에이전트가 처리할 많은 작업을 큐에 넣었다.”
“인간의 day shift가 계획을 준비하고, AI의 night shift가 AFK로 작업한다.”
17. Ralph Loop와 로컬 이슈 기반 구현
발표자는 Ralph Loop라는 구현 루프를 설명합니다.
로컬 issues 디렉터리에 있는 마크다운 이슈들을 읽고, 최근 커밋 정보를 함께 가져온 뒤, Claude Code에 넘겨 작업하게 합니다.
초기 버전은 단일 실행 스크립트입니다. 나중에는 Docker sandbox와 반복 루프로 확장할 수 있습니다.
AI는 다음 순서로 작업을 고릅니다.
- 치명적 버그
- 개발 인프라
- Tracer bullet
- 작은 개선과 리팩터링
주요 발언
“우리는 AFK 에이전트가 집어갈 백로그를 만들고 있다.”
“처음에는 한 번만 실행해서 에이전트가 어떻게 일하는지 보는 것이 중요하다.”
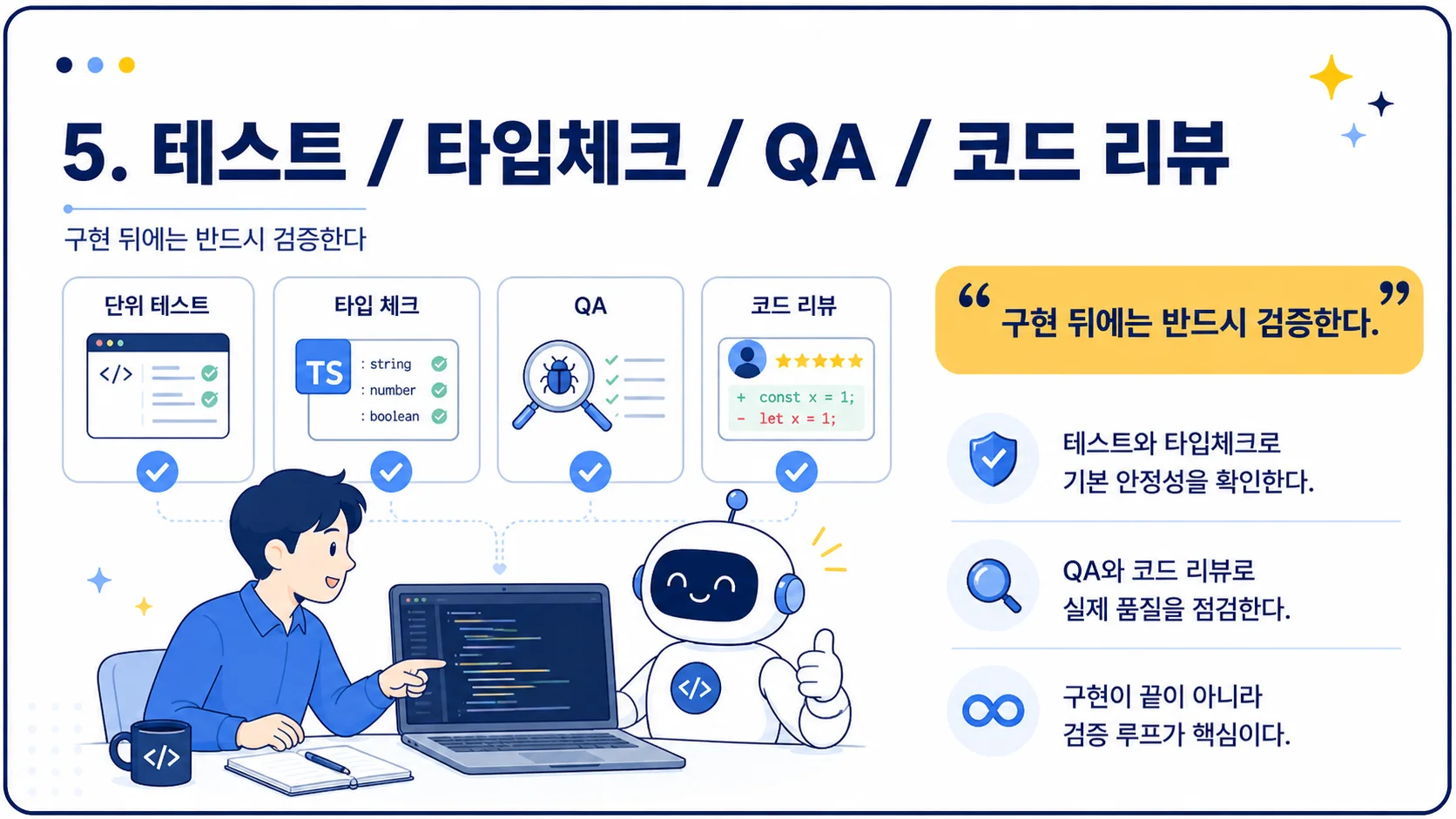
18. 코드 리뷰 부담은 줄어들지 않는다
Q&A에서 발표자는 AI를 쓰면 코드 리뷰가 더 많아지는 문제를 인정합니다.
AI가 많은 코드를 생산하면, 사람이 검토해야 할 코드도 많아집니다. 작은 PR 원칙과 AI의 대량 구현 사이에는 긴장이 생깁니다.
발표자는 이 문제에 대해 완벽한 답은 없지만, 앞으로 개발자들이 더 많은 코드 리뷰를 하게 될 가능성이 크다고 말합니다.
주요 발언
“AI에게 코딩을 위임한다면, 구현 뒤에는 QA와 코드 리뷰가 필요하다.”
“솔직히 아직 답을 모르겠다. 우리는 더 많은 코드 리뷰를 할 준비를 해야 할 것 같다.”
19. 팀 작업에서의 적용
현실의 팀 작업은 선형적이지 않습니다. 아이디어가 병렬로 들어오고, 도메인 전문가와의 논의, 프로토타입, 리서치, 아키텍처 검토가 계속 오갑니다.
발표자는 PRD와 여정 설계 전까지는 팀과 계속 논쟁하고 피드백을 받아야 한다고 설명합니다. 이 단계의 산출물은 공유되고, 검토되고, 수정되는 대상입니다.
주요 발언
“아이디어에서 목적지까지 가는 여정은 팀과 함께 찾아야 한다.”
“PRD와 journey까지는 팀 피드백이 필요한 영역이다.”
“어디로 가야 하는지 알게 된 뒤에야 칸반 보드와 구현으로 넘어갈 수 있다.”
20. 프론트엔드 작업: AI에게 완성 UI를 맡기기보다 프로토타입을 만들게 하라
발표자는 프론트엔드는 AI에게 특히 어렵다고 말합니다. 이유는 프론트엔드는 시각적이고, 인간의 눈으로 봐야 하는 요소가 많기 때문입니다.
Playwright MCP나 agent browser 같은 도구로 AI가 화면을 보게 할 수는 있지만, 아직 성숙한 코드베이스에서 좋은 UI를 스스로 만들어내는 수준은 아니라고 평가합니다.
대신 AI에게 여러 개의 throwaway prototype을 만들게 하고, 사람이 그중 좋은 방향을 고른 뒤 다시 Grill Me 세션이나 설계 과정에 반영하는 방식을 제안합니다.
주요 발언
“프론트엔드는 인간의 눈이 계속 필요하다.”
“AI는 아직 성숙한 코드베이스에서 좋은 프론트엔드를 만들기에 충분히 좋지 않다.”
“대신 클릭해볼 수 있는 세 개의 throwaway prototype을 만들게 하고, 그중 좋은 것을 고르면 된다.”
21. TDD와 피드백 루프의 중요성
발표자는 AI 코딩에서 TDD와 테스트 피드백 루프가 매우 중요하다고 강조합니다.
AI는 테스트, 타입체크, lint 같은 피드백 루프가 없으면 사실상 눈먼 상태로 코딩합니다. 반대로 피드백 루프가 좋으면 AI가 스스로 오류를 찾고 고칠 수 있습니다.
발표자는 코드베이스의 피드백 루프 품질이 AI 코딩 품질의 상한선을 결정한다고 말합니다.
주요 발언
“피드백 루프는 AI가 합리적인 결과를 내는 데 필수적이다.”
“피드백 루프가 없으면 AI는 완전히 눈먼 상태로 코딩한다.”
“AI 출력이 나쁘다면, 피드백 루프의 품질을 높여야 할 때가 많다.”
22. Push와 Pull: 코딩 표준을 AI에게 전달하는 방법
아키텍처, 코딩 표준, API 계약, 보안 규칙을 AI에게 어떻게 지키게 할 것인가에 대해 발표자는 Push / Pull 개념을 설명합니다.
Push는 Claude.md 같은 파일에 지침을 넣어 항상 AI에게 전달하는 방식입니다. Pull은 AI가 필요할 때 skill이나 문서를 찾아보게 하는 방식입니다.
발표자는 구현 에이전트에게는 Pull 방식이 적합하고, 리뷰 에이전트에게는 Push 방식이 적합하다고 말합니다.
구현자는 필요할 때 표준을 참조하면 되고, 리뷰어는 반드시 코딩 표준과 작성된 코드를 비교해야 하기 때문입니다.
주요 발언
“Push는 지침을 LLM에게 밀어 넣는 것이다.”
“Pull은 에이전트가 필요할 때 정보를 가져올 기회를 주는 것이다.”
“구현 에이전트에게는 coding standards를 pull 가능하게 두고, 리뷰어에게는 push해야 한다.”
23. Sand Castle: 병렬 AFK 에이전트 실행
발표자는 자신이 만든 Sand Castle이라는 TypeScript 라이브러리를 소개합니다.
이 도구는 에이전트를 AFK로 실행하기 위한 구조입니다. Git worktree를 만들고, Docker container 안에서 sandboxing한 뒤, 각 브랜치에서 프롬프트를 실행합니다.
흐름은 다음과 같습니다.
- Planner가 백로그에서 병렬로 처리할 이슈를 고름
- 각 이슈마다 sandbox 생성
- Implementer가 각 sandbox에서 작업
- 커밋이 생기면 Reviewer가 검토
- Merger agent가 브랜치를 병합
- 타입과 테스트 문제가 있으면 해결
주요 발언
“Sand Castle은 AFK 에이전트 루프를 실행하기 위한 TypeScript 라이브러리다.”
“각 이슈마다 sandbox를 만들고, 그 안에서 구현을 실행한다.”
“이 흐름을 통해 여러 에이전트에 걸쳐 병렬화할 수 있다.”
24. 마무리: 전체 워크플로우 요약
발표자는 마지막에 전체 흐름을 다시 정리합니다.
이 방식은 specs-to-code 컴파일러가 아닙니다. AI가 그냥 코드를 찍어내게 하는 방식도 아닙니다.
사람은 코드베이스의 구조를 계속 의식해야 합니다. Grill Me로 AI와 정렬하고, PRD로 목적지를 문서화하고, 칸반 보드로 병렬 가능한 이슈를 만들고, 에이전트가 구현하게 하고, 사람은 QA와 코드 리뷰를 강하게 수행합니다.
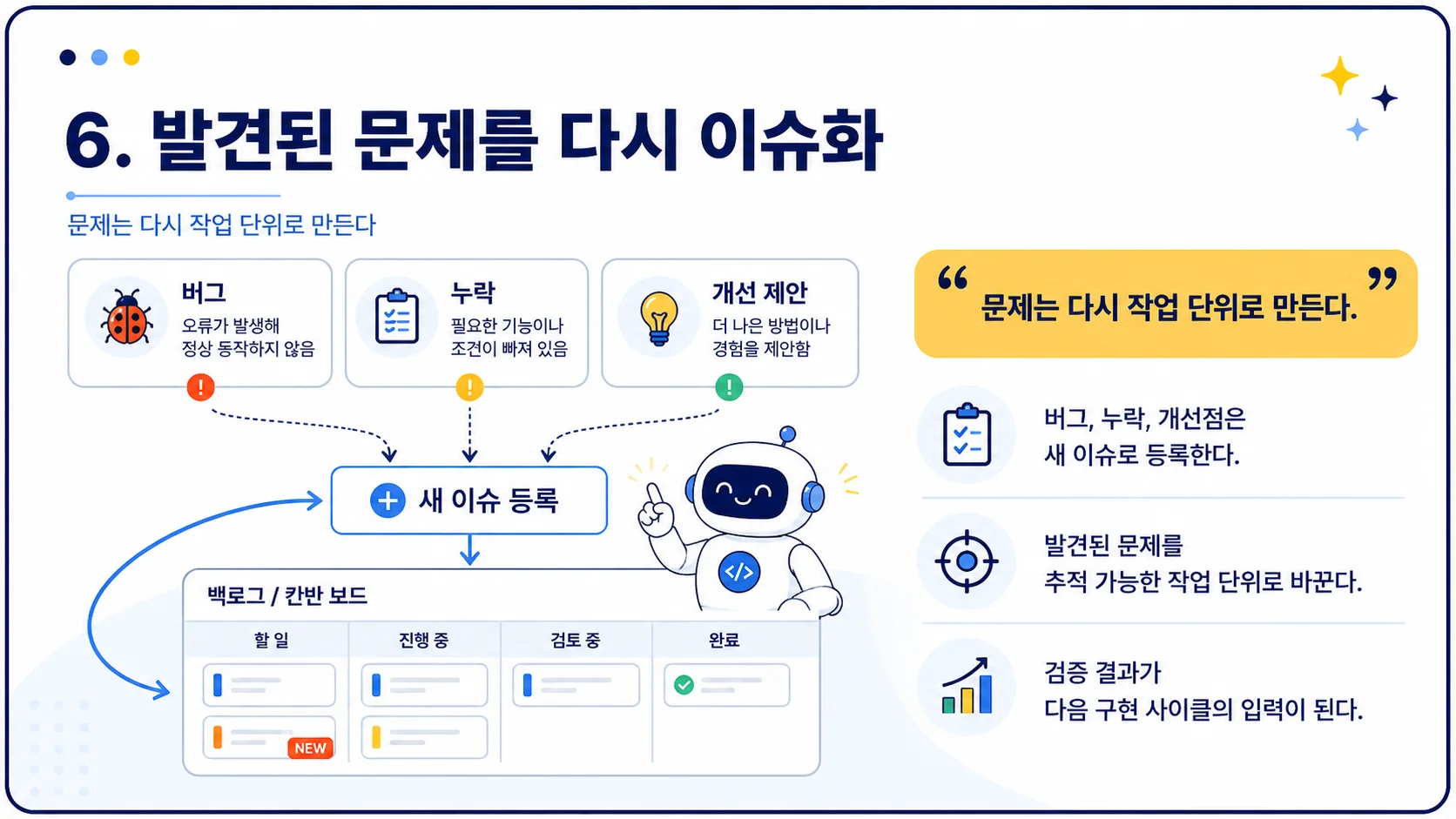
또한 QA 단계에서 발견한 문제는 다시 칸반 보드의 이슈로 추가됩니다. 즉, 구현과 QA는 계속 순환합니다.
주요 발언
“이것은 specs-to-code compiler가 아니다.”
“우리는 코드베이스의 모듈과 형태를 매우 의도적으로 설계하고 있다.”
“Grilling session으로 최대한 정렬하고, PRD로 만들고, 병렬화 가능한 이슈로 바꾼다.”
“구현한 뒤에는 QA와 코드 리뷰를 강하게 하고, 다시 구현 루프로 돌린다.”
핵심만 압축하면
이 발표는 AI 코딩을 이렇게 하라는 이야기입니다.
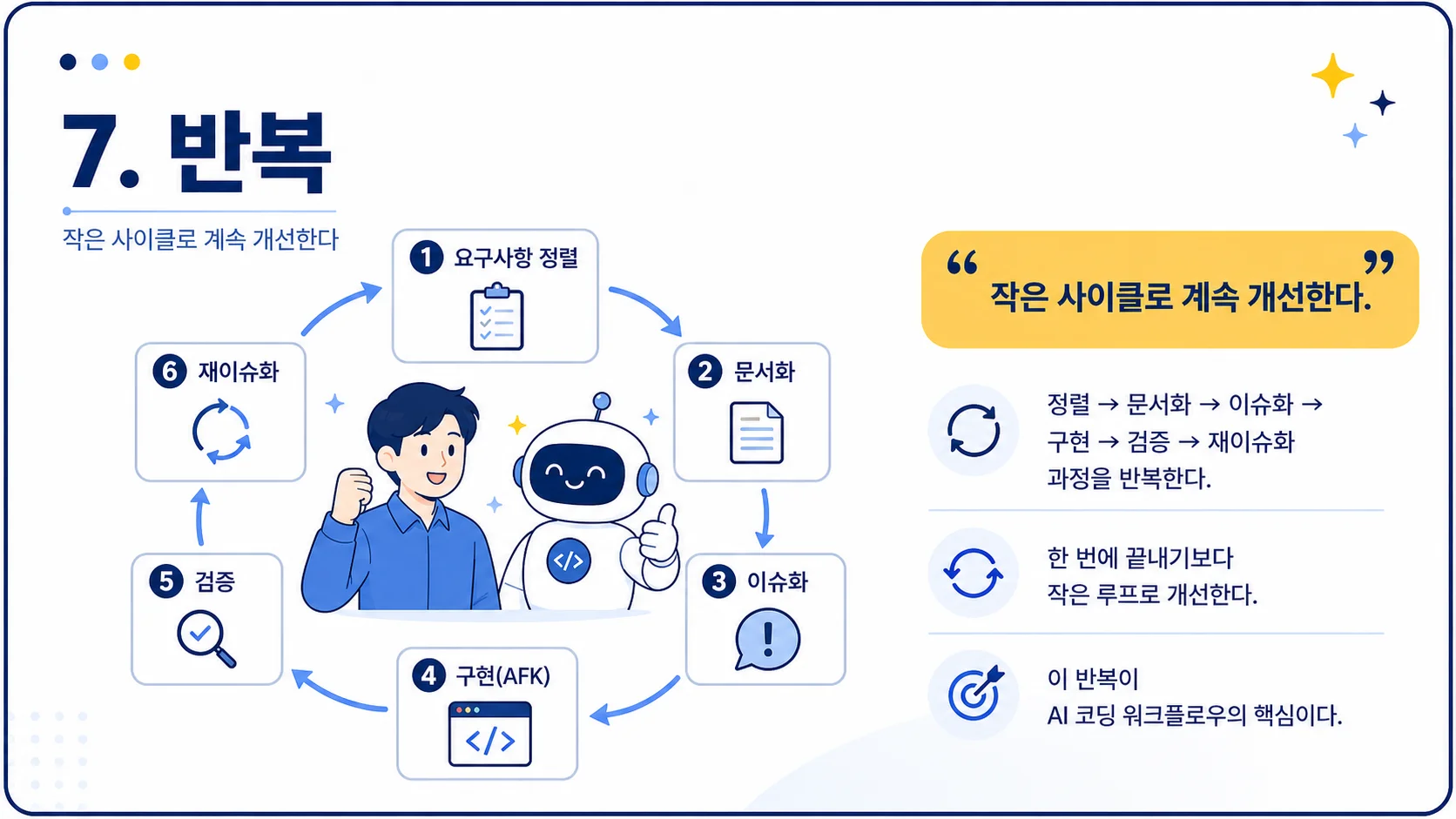
아이디어→
Grill Me로 AI와 요구사항 정렬→
PRD로 목적지 문서화→
Vertical Slice 기반 칸반 이슈 생성→
AFK 에이전트가 구현→
테스트 / 타입체크 / QA / 코드 리뷰→
발견된 문제를 다시 이슈화→
반복실무적으로 중요한 포인트는 이겁니다.
AI 코딩의 핵심은 프롬프트 한 방이 아니라, AI가 실패하지 않도록 작업 단위·문서·테스트·리뷰 루프를 설계하는 것이다.